离散概率空间 vs 线性空间
概率必须非负、总和为 1——这不是线性空间。但 softmax 之前的 logit 空间是自由的。从黑白球实验中看到从"三角形"到"全平面"的跨越。
实验设计
设样本空间为 10 次放回取样。两组实验:
| 组别 | 颜色 | 可能结果 | 概率分布 |
|---|---|---|---|
| A | 黑白 | $$\{黑, 白\}$$ | $$p_{黑} + p_{白} = 1$$ |
| B | 黑白灰 | $$\{黑, 白, 灰\}$$ | $$p_{黑} + p_{白} + p_{灰} = 1$$ |
10 次放回后,各组得到一个频率向量:
A 组: (黑=6, 白=4) → 经验概率 p = (0.6, 0.4)
B 组: (黑=6, 白=3, 灰=1) → 经验概率 p = (0.6, 0.3, 0.1)
这个向量
$$\mathbf{p}$$生活在概率单纯形上。
单纯形不是线性空间
A 组(二分类)
二分类的概率分布只有一个自由度:
$$p_{黑} = p, \quad p_{白} = 1-p, \quad 0 \leq p \leq 1$$这个空间是实数轴上的一个线段:
p=0: ○白 p=0.5: ●──○ p=1: ●黑
[0, 1] 区间,两端封闭
线性空间要求:任意线性组合还在空间内。但这里:
- $$p = 0.5$$ 在空间中(黑白各半)
- $$p = -0.5$$ 不在空间中(概率不能为负)
- $$p = 1.5$$ 不在空间中(概率不能大于 1)
所以概率单纯形 不是 线性空间——它是有界闭凸集。
B 组(三分类)
三分类的概率分布在二维平面上是一个三角形(2-单纯形):
白
● (0,1,0)
/ \
/ \
/ \
/ \
(1,0,0)●─────────●(0,0,1)
黑 灰
三点分别对应三组极端情况。内部任意一点对应一个有效概率分布。但这个空间仍然被边界封锁——你不能有负概率,也不能让总和超过 1。
Softmax:从三角形到全平面
Softmax 的参数是 logits
$$\mathbf{z} \in \mathbb{R}^k$$,没有任何约束:
z = (z_黑, z_白) A 组: z ∈ ℝ²,完全自由
z = (z_黑, z_白, z_灰) B 组: z ∈ ℝ³,完全自由
通过 softmax:
$$p_i = \frac{e^{z_i}}{\sum_j e^{z_j}}$$| z 空间 | p 空间 | |
|---|---|---|
| 约束 | 无 | $$p_i \geq 0, \sum p_i = 1$$ |
| 范围 | $$z_i \in (-\infty, +\infty)$$ | $$p_i \in [0, 1]$$ |
| 线性? | 是 | 否 |
| 加法封闭 | ✅ $$z_1 + z_2 \in \mathbb{R}$$ | ❌ $$p+q$$ 不再归一化 |
| 数乘封闭 | ✅ $$2z \in \mathbb{R}$$ | ❌ $$2p$$ 不再归一化 |
Softmax 把一个无约束的线性空间映射到了有约束的单纯形上。
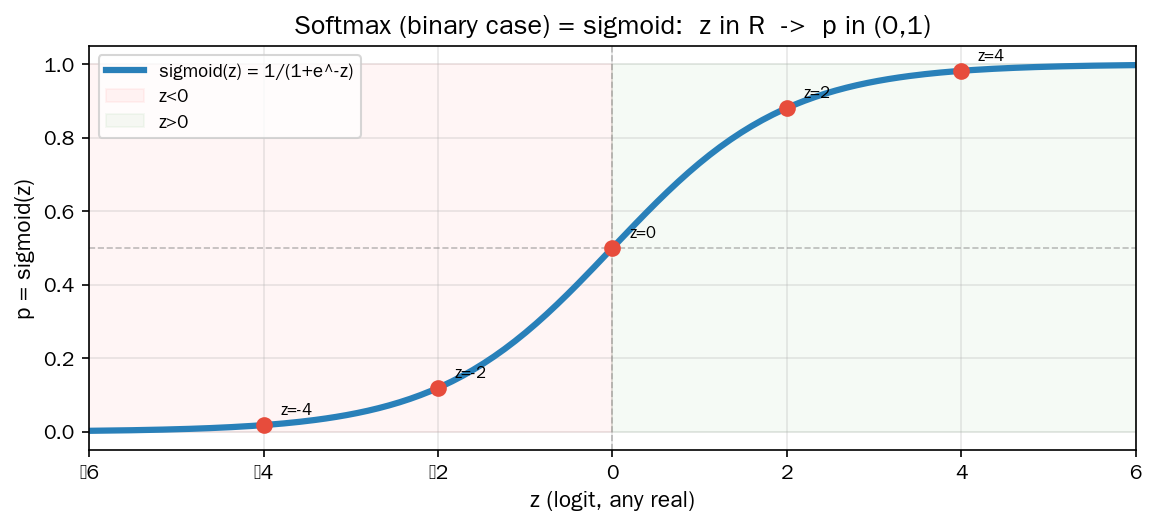
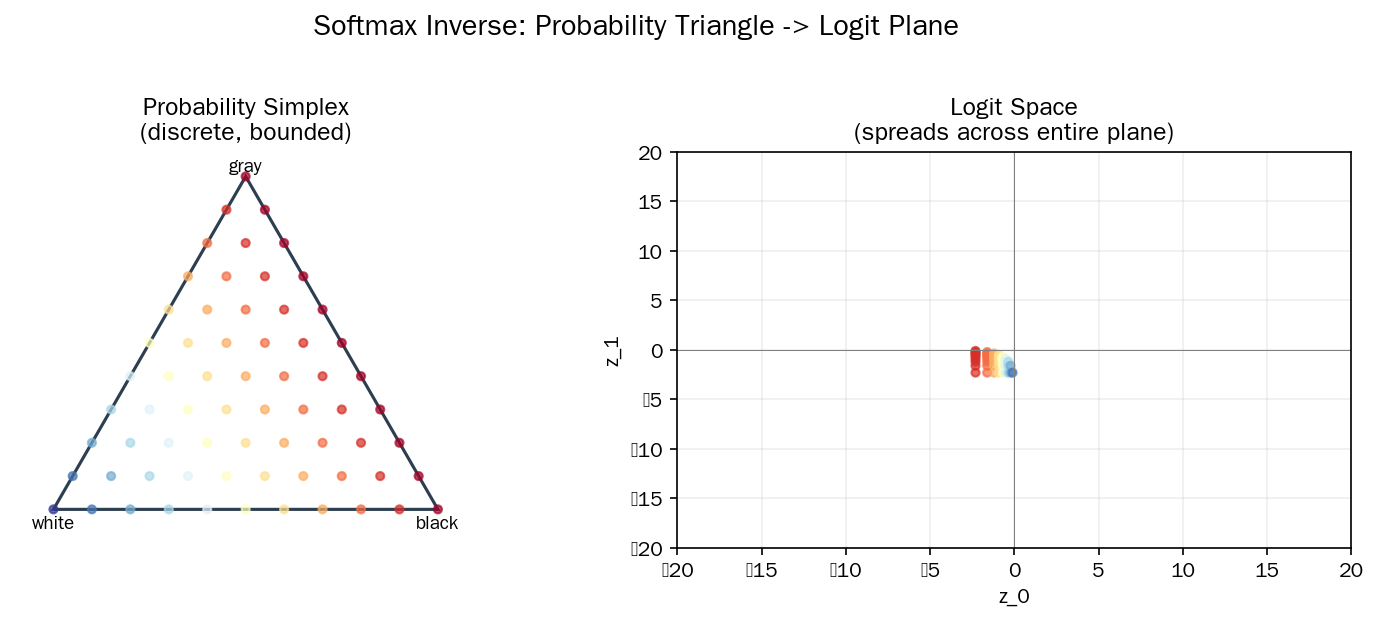
图2 A 组(二分类)的概率空间是一条线段 [0,1],而 logit 空间是整个实数轴:
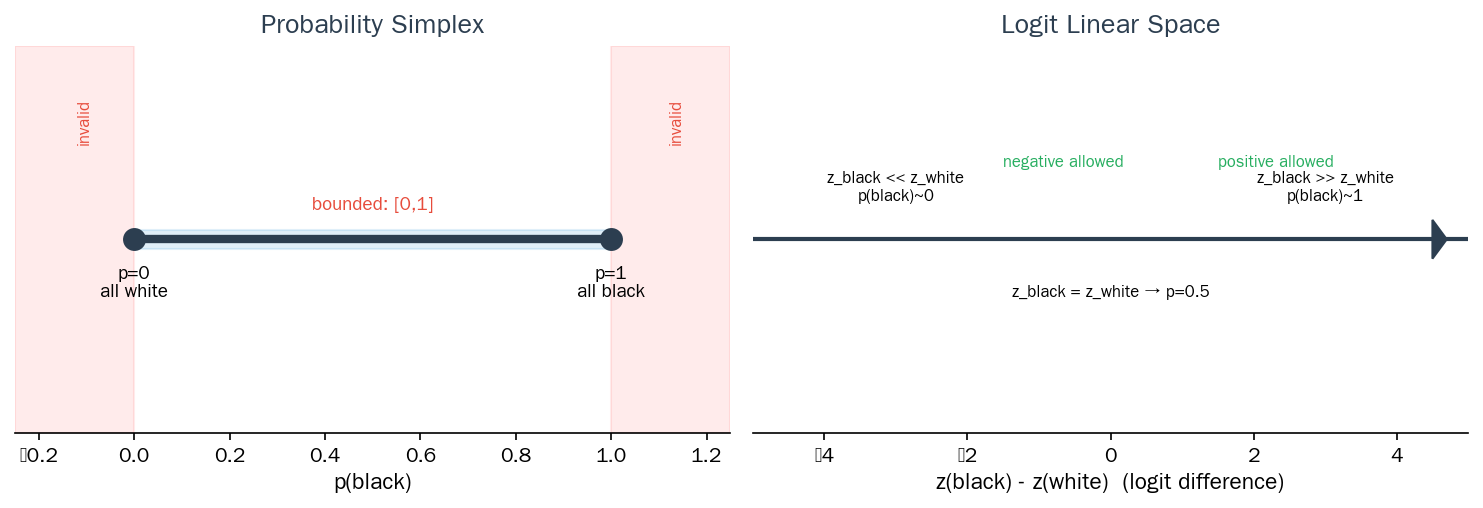
图3 B 组(三分类)的概率空间是一个三角形(2-单纯形),内部每个点对应一个有效概率分布:
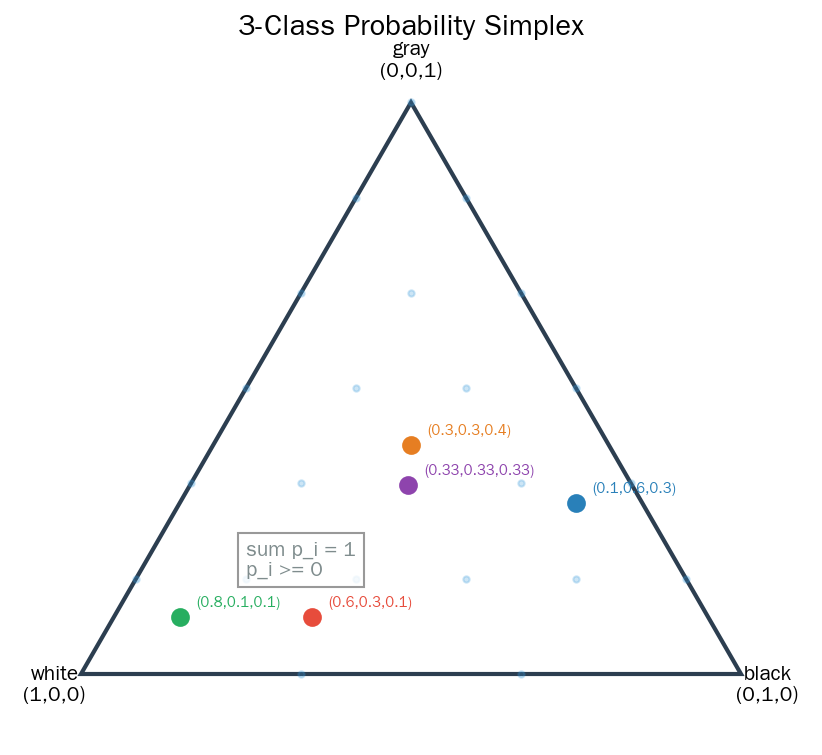
图4 同一组 logits 在 ℝ³ 里自由行走,softmax 把它们映射到概率空间——一条自由的路径被限制在了三角形内:
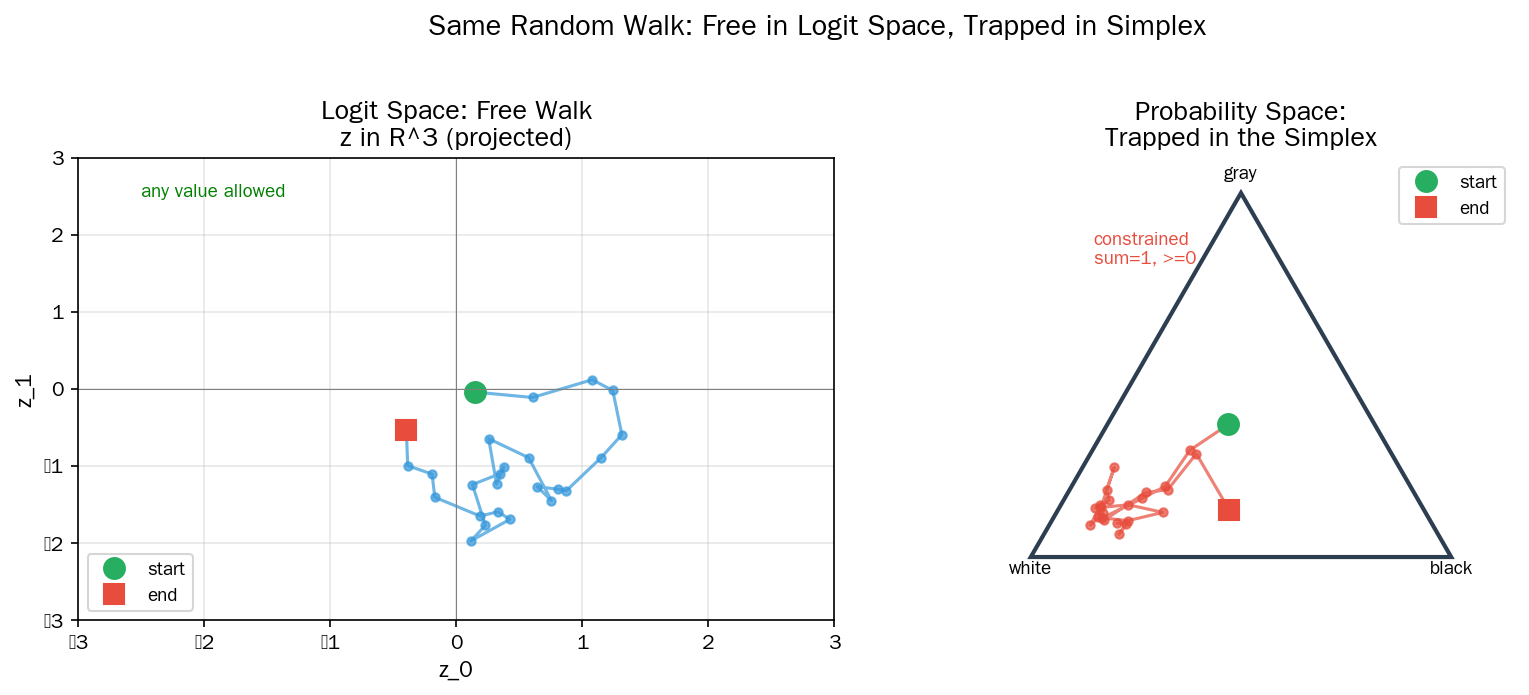
图5 对数变换(log)将概率空间均匀铺满的网格映射到整个平面:
点彩实验:概率密度如何在 logit 空间展开
取 6:3:1 的三色球(黑:白:灰),每次 10 次放回取样,重复 5000 组。每一组得到频数计数
$$(c_1, c_2, c_3)$$,计算经验概率
$$p_i = c_i / N$$。然后通过 log-ratio 变换反算出对应的 logit 坐标。
为了避免
$$c_i=0$$时
$$\log(p_i)$$出现
$$-\infty$$,实验中过滤掉了含零计数的样本,并对所有概率做了微小平移(Laplace 平滑)。
softmax 前向的定义是:
$$p_i = \frac{e^{z_i}}{\sum_{j=1}^k e^{z_j}} = \frac{e^{z_i}}{Z}, \qquad Z = \sum_{j=1}^k e^{z_j}$$两边取对数:
$$\log p_i = z_i - \log Z$$移项得到逆映射:
$$z_i = \log p_i + \log Z$$这里
$$\log Z$$是对所有类都相同的常数(log-partition function)。softmax 对 logits 的全局平移不敏感:
$$\text{softmax}(z_1, z_2, z_3) = \text{softmax}(z_1 + c, z_2 + c, z_3 + c)$$所以有效自由度只有
$$k-1$$。我们通常以第三类(灰)为参考,设
$$z_3 = 0$$,则:
$$z_i = \log\frac{p_i}{p_3}, \quad i = 1, 2$$这就是代码中 z_rel = z[:, :2] - z[:, 2:3] 的含义——在 logit 平面上,点坐标是
,完全消除了平移常数的不确定性。
把
$$\mathbf{p}$$画在三角形上,
$$\mathbf{z}$$画在平面上——空间变了,点的密度也跟着变了。
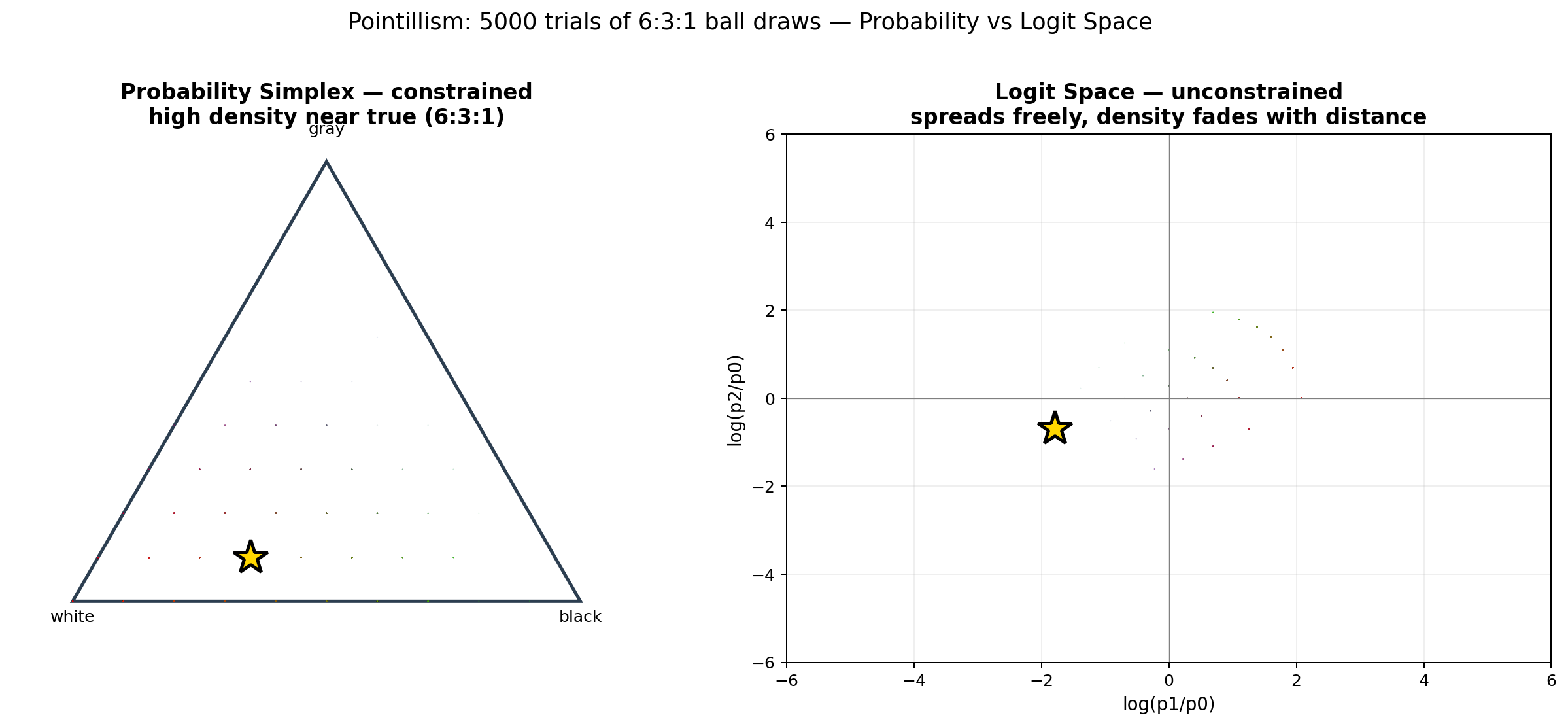
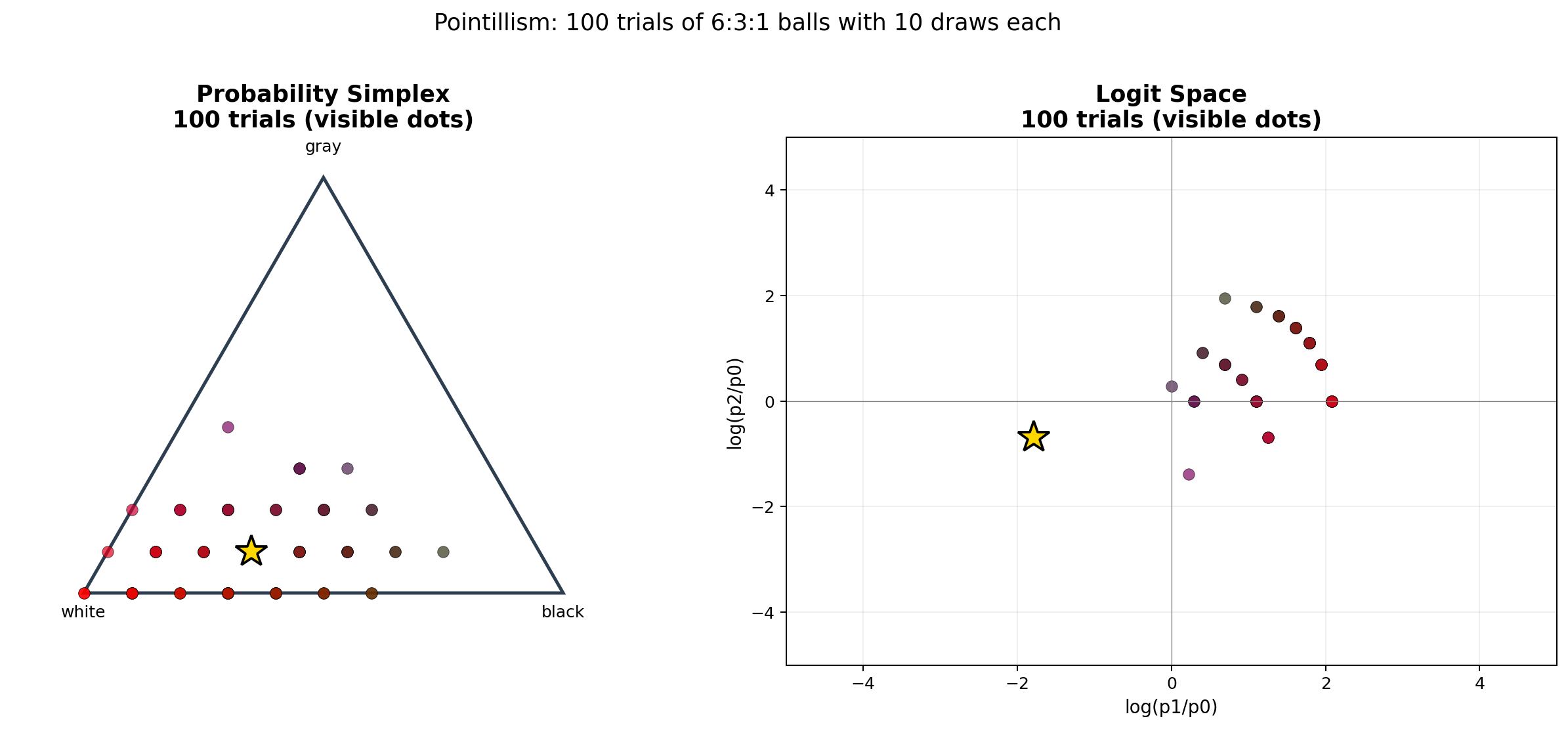
关键观察:
- 概率空间(左):点被锁在三角形里。靠近真实分布
(0.6, 0.3, 0.1)的地方点最密——那是采样回落到真值的区域。 - Logit 空间(右):点散布在整个平面上。三角形中心的密集区域映射到了平面上的某一团,而三角形边缘(概率接近 0 或 1 的点)映射到了很远的地方——log 把靠近边界的点推到了平面上很远的位置。
这张点彩图回答了上面 “负 logits 是否只是输入合法性” 的问题——不只是合法性。logit 的绝对正负没有直接概率意义,概率由 logits 之间的差值决定:在二分类固定参考 logit 为 0 时,负差值对应概率小于 0.5。真正的概率密度团簇在 logit 空间里变成了椭圆状的云,而三角形边缘的稀疏地带变成了平面的散落尘埃。
这就是对数变换的效果——三角形上的均匀网格被映射到对数空间后,网格在远处变得稀疏,在中心变得密集。这是一个非线性的坐标变换(不是等距映射),把单纯形内部展开到 log-ratio 坐标空间。
为什么 logit 点不是遍布全平面?
这个问题很有价值——也是点彩图能揭示的最关键的 insight。
每次只有 10 次放回取样,这意味着经验概率是量化的:(黑, 白, 灰) 的计数是 0 到 10 的整数,且总和必须等于 10。三个数满足这个约束有多少种?
实际 5000 次试验只命中了其中 44 种组合。log(p) 把这 44 种离散组合映射到平面上 44 个点——所以点看起来聚在几个团里。
提高每组次数会发生什么?
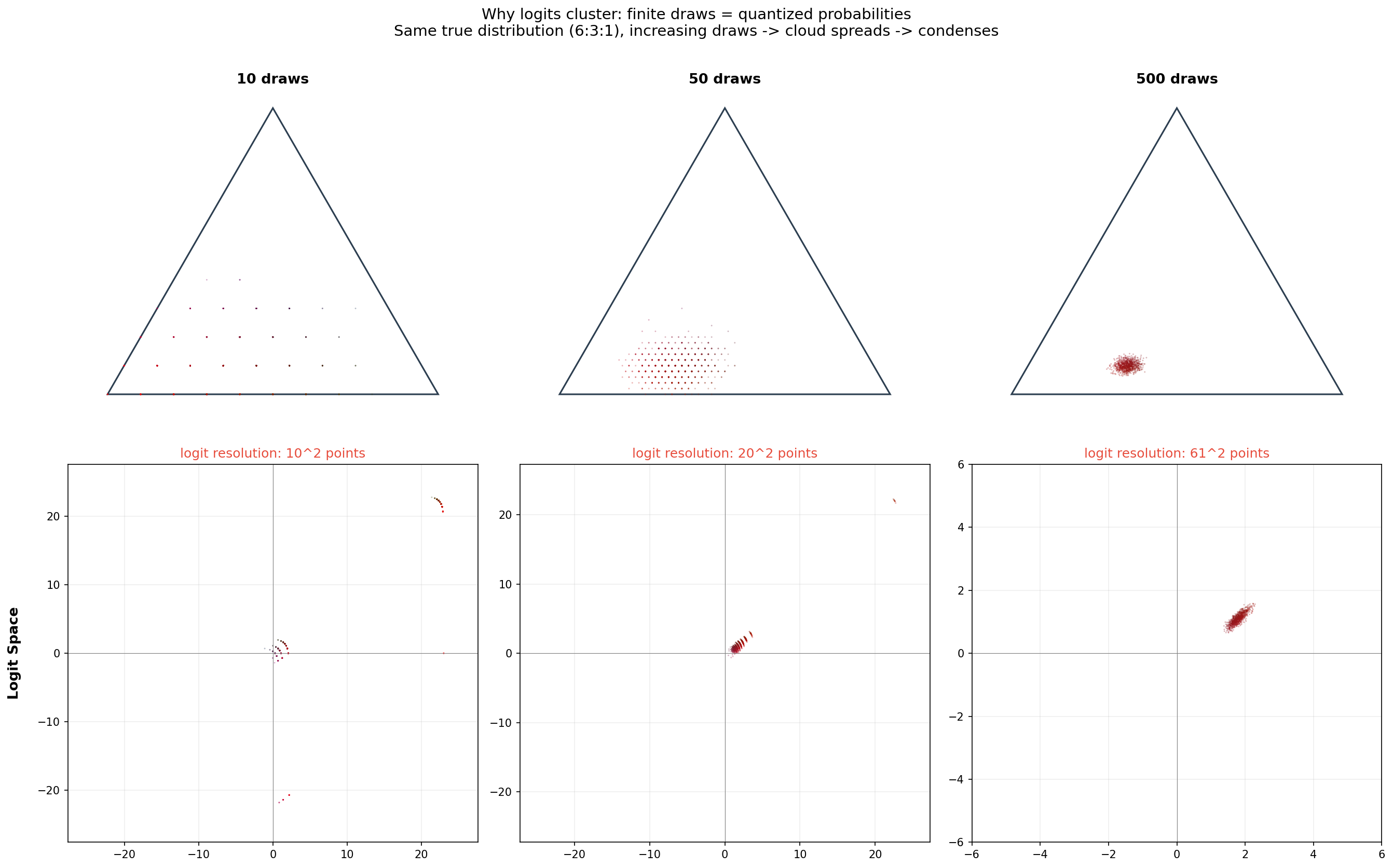
10 次和 50 次时,概率是粗量化的——logit 点被限制在有限的格子上。到 500 次时,概率几乎是连续的,logit 点开始覆盖整个区域。但注意:所有点仍然围绕真实分布 (6:3:1) 形成的等高线,因为采样源自同一个真实分布。
要想 logit 点真正覆盖整个 ℝ² 平面,需要变化真实分布本身。当一个神经网络在训练时,参数的每次更新都在改变 logits——logit 空间确实可以收敛到任何位置。点彩图展示的是采样分布,不是空间的界限。
可视化:logits 的自由度
A 组(二分类)实际上自由度是 1——softmax 对 logits 平移不敏感:
$$\text{softmax}(z_1 + c, z_2 + c) = \text{softmax}(z_1, z_2)$$所以有效自由度 = k − 1。但关键是:这 k−1 个自由度取任意实数值,不需要在 [0, 1] 内。
| 概率 p | Logit z | |
|---|---|---|
| A 组(2 色) | 线段 [0,1] | ℝ¹ 全线 |
| B 组(3 色) | 三角形内部 | ℝ² 全平面 |
| 允许负值? | ❌ | ✅ |
| 允许 >1? | ❌ | ✅ |
代码验证
import torch
import torch.nn.functional as F
# === A 组:黑白球,10 次放回 ===
print("=== A组 黑白二分类 ===")
counts_a = torch.tensor([6, 4], dtype=torch.float32)
p_a = counts_a / counts_a.sum()
print(f"概率 p: {p_a}")
# 从概率计算 logits(加 log,再中心化)
logits_a = torch.log(p_a)
print(f"logits z: {logits_a}")
print(f"softmax(z): {F.softmax(logits_a, dim=-1)}")
# 验证:logits 可以取任意值,softmax 仍然有效
for val in [-5, -2, 0, 2, 5]:
z_test = torch.tensor([val, 0.0])
p_test = F.softmax(z_test, dim=-1)
print(f" z=({val:3d}, 0) → p=({p_test[0]:.4f}, {p_test[1]:.4f})")
# 验证:概率空间有限制,logit 空间无限制
# p 必须满足 p∈[0,1], 但 z 可以是任何数
print(f"\n概率 p 的取值范围: [0, 1]")
print(f"logits z 的取值范围: (-∞, +∞) ← 线性空间")
# === B 组:黑白灰球,10 次放回 ===
print("\n=== B组 黑白灰三分类 ===")
counts_b = torch.tensor([6, 3, 1], dtype=torch.float32)
p_b = counts_b / counts_b.sum()
print(f"概率 p: {p_b}, 总和={p_b.sum().item()}")
logits_b = torch.log(p_b)
print(f"logits z: {logits_b}")
print(f"softmax(z): {F.softmax(logits_b, dim=-1)}")
# 验证:概率只能走三角形内部,logits 可以走全平面
print("\n概率空间的移动(沿边界):")
p_moves = [
(0.8, 0.15, 0.05),
(0.5, 0.4, 0.1),
(0.3, 0.3, 0.4),
]
for p in p_moves:
p_t = torch.tensor(p)
z_t = torch.log(p_t)
print(f" p=({p[0]:.1f},{p[1]:.1f},{p[2]:.1f}) ← z=({z_t[0]:.1f},{z_t[1]:.1f},{z_t[2]:.1f})")
print("\nLogits 空间的自由行走(允许负数、允许任意值):")
z_moves = [
(5.0, 0.0, -2.0),
(-1.0, 3.0, 0.5),
(0.0, 0.0, 0.0),
]
for z in z_moves:
z_t = torch.tensor(z)
p_t = F.softmax(z_t, dim=-1)
print(f" z=({z[0]:.1f},{z[1]:.1f},{z[2]:.1f}) → p=({p_t[0]:.3f},{p_t[1]:.3f},{p_t[2]:.3f})")
输出:
=== A组 黑白二分类 ===
概率 p: tensor([0.6000, 0.4000])
logits z: tensor([-0.5108, -0.9163])
softmax(z): tensor([0.6000, 0.4000])
# logits 可以取任意值,softmax 仍然有效
z=( -5, 0) → p=(0.0067, 0.9933)
z=( -2, 0) → p=(0.1192, 0.8808)
z=( 0, 0) → p=(0.5000, 0.5000)
z=( 2, 0) → p=(0.8808, 0.1192)
z=( 5, 0) → p=(0.9933, 0.0067)
概率 p 的取值范围: [0, 1]
logits z 的取值范围: (-∞, +∞) ← 线性空间
=== B组 黑白灰三分类 ===
概率 p: tensor([0.6000, 0.3000, 0.1000]), 总和=1.0
logits z: tensor([-0.5108, -1.2040, -2.3026])
softmax(z): tensor([0.6000, 0.3000, 0.1000])
Logits 空间的自由行走:
z=(5.0, 0.0, -2.0) → p=(0.993, 0.007, 0.001)
z=(-1.0, 3.0, 0.5) → p=(0.014, 0.776, 0.210)
z=(0.0, 0.0, 0.0) → p=(0.333, 0.333, 0.333)
时域与频域:不可同时精确,但可以同时学习
回到最开始的问题:词袋模型只统计"哪个词出现多少次"(频域),完全丢失了"谁挨着谁"(时域)。看这两句中文:
“我的确累了” “我的的确确累了”
“的确"在第一句出现一次,在第二句出现两次。模型可以学习到这种频率变化影响 logits,softmax 再把这些 logits 转成概率或注意力权重——但频率域无法捕捉 “的→的确→确” 的 AABB 叠词邻接模式。
信号处理里的应对是短时傅里叶变换(STFT)——为每个窗口生成局部频谱。可以做一个类比:Transformer 的 Self-Attention 类似 STFT,为每个位置动态地选择关注哪些上下文。但数学上 Attention 不是傅里叶变换——它做的是基于 query-key 相似度的加权求和。
| 信号处理 | 概率/ML | 解决的问题 |
|---|---|---|
| 时域 $$f(t)$$ | 词序列 “我-的确-累了” | 谁挨着谁 |
| 频域 $$F(\omega)$$ | 词袋概率 softmax(p) | 哪个词重要 |
| 时频域 STFT | 类比 Attention | 两种信息结合 |
结论
| 概念 | 数学空间 | 特性 | 不是线性空间的原因 |
|---|---|---|---|
| 概率 $$\mathbf{p}$$ | (k-1)-维单纯形 | $$\sum p_i = 1, p_i \geq 0$$ | 有界闭凸集:加法、数乘、任意线性组合不封闭 |
| Logits $$\mathbf{z}$$ | $$\mathbb{R}^k$$ | $$z_i \in (-\infty, \infty)$$ | ✅ 无约束,线性封闭 |
| Softmax | $$\mathbb{R}^k \to \text{int}(\Delta^{k-1})$$ | 前向:exp + 归一化,只覆盖单纯形内部 | — |
| log-ratio | $$\Delta^{k-1} \to \mathbb{R}^{k-1}$$(严格正概率) | $$u_i = \log(p_i/p_k)$$,无约束坐标 | ✅ |
Softmax 做的事:把一个无约束的欧几里得空间映射到概率单纯形的内部(边界点只能作为 logit 极限逼近)。反过来,log-ratio 变换把严格正的概率分布拉到无约束坐标空间。
这就是分类任务能用梯度下降的根本原因——模型在 logit 空间(线性)里做参数更新,softmax 保证更新后的 logits 总能变成有效的概率分布。如果你直接在概率空间里做梯度下降,你会撞墙:概率不能为负、不能大于 1、必须保持总和为 1——三个约束锁死了优化。
回到 WMT:翻译模型在 56K 维的 logit 空间里自由行走(梯度可以大胆地更新任何 logit),softmax 把每一步更新映射到 56K 维的概率单纯形上。K_lang 限制 softmax 分母相当于缩小了单纯形的有效维度——从 56652 维缩到 170 维。
May the Code be with us.
License: GPLv3
本文《Watermelon》系列采用 GNU 通用公共许可证第三版 (GNU General Public License v3.0) 协议进行开源发布与分发。