Attention Phase 2——从时序链到邻接矩阵,再到 K_lang 碰撞
RNN 的悲剧不是 hash 桶不够大——是 50 个词共用一条链。Attention 解决了图的问题。但 SoftBLEU 遇到了新问题。
Phase 2 实验总览:SoftBLEU 在 Attention 上失效
H=256, E=256, epochs=5, 64 batch, Attention decoder:
| 实验 | 损失函数 | 最佳 BLEU | 注 |
|---|---|---|---|
| A1 | 纯 CE | 3.76 | peak ep2, 倒U过拟合 |
| A2 | 纯 CE, ep=10 | 3.76 | ep2后持平不涨 |
| A3 | 纯 CE, H=512 | 3.94 | 大模型有收益 |
| A4 | CE+SB 50/50 | 3.50 | 梯度拉锯,反降 |
| A5 | 纯 SB (−log BLEU) | 0.00 | soft匹配 vs argmax解码 鸿沟 |
| A6 | CE+0.5×(1−BLEU) E6配方 | 3.74 | 未破CE天花板 |
| A7 | CE+0.1×(1−BLEU) | 待补 | 微量混合 |
| A8 | 双头梯度相乘 | 3.76 | 与纯CE完全一致 |
关键发现: SoftBLEU 在 RNN 上 +0.15 (3.06→3.21)。在 Attention 上增益归零。不是 SoftBLEU 的公式错了——是在 56K vocab 上梯度被稀释到了噪声水平。
问题不在 SoftBLEU 的函数形式——在梯度量级
CE 梯度:dCE/dlogit[target] = softmax(target) − 1 ≈ −1
SoftBLEU 梯度:
$$\frac{\partial \text{SB}}{\partial \text{logit}[i]} = \sum_{c \in \text{ref}} \text{softmax}(c) \times (\delta_{ic} - \text{softmax}(i))$$其中 softmax(c) ≈ 1/56652 ≈ 1.8×10⁻⁵。20 个 ref token 累加后 ≈ 3.6×10⁻⁴。
SoftBLEU 梯度 / CE 梯度 ≈ 1/2800。
在 RNN 上 SB 有 0.15 增益,因为 RNN 的 CE 本身只有 3.06——有足够空间被纠正。在 Attention 上 CE 已到 3.76,2800:1 的梯度差让 SB 信号完全沉没。
K_lang:语言系统的碰撞常数
第 4 层 hash (vocab) 的碰撞空间:
K_lang ≈ 0.003
有效碰撞词数 = K_lang × |V| = 0.003 × 56652 ≈ 170
56K 词汇表里,有意义的碰撞只发生在 ~170 个词之间。其余 56K−170=56482 个词对翻译质量无影响——但在 softmax 分母里均匀稀释梯度。
SoftBLEU 不该在全表上做 softmax——应该在 170 个碰撞桶上做。
Restricted Softmax:把分母从 56K 缩到 170
# 旧:softmax 分母在全表 56652 上求和
probs = softmax(logits, dim=-1) # 每个 token 概率 ≈ 1.8e-5
# 新:softmax 分母只在 topk + ref ∪ 上求和
topk_idx = topk(logits, k=170)
restricted = fill(-inf) + topk + ref_tokens
probs = softmax(restricted, dim=-1) # 每个 token 概率 ≈ 0.006
梯度放大 333 倍:
| 方案 | 分母 | 每 token 概率 | 梯度放大 |
|---|---|---|---|
| 全表 softmax | 56652 | ~1.8×10⁻⁵ | 1× |
| Restricted k=50 | 50 | ~0.02 | ~1130× |
| Restricted k=170 | 170 | ~0.006 | ~333× |
| Restricted k=500 | 500 | ~0.002 | ~113× |
双头架构与损失函数
定义
设 $T$ 为目标句长,$V$ 为词表大小(56,652),$\alpha$ 为 SB 权重:
$$\mathcal{L} = \mathcal{L}_{\text{CE}} \cdot \big(1 + \alpha \cdot (1 - \text{SB})\big)$$其中:
$$\mathcal{L}_{\text{CE}} = -\frac{1}{T}\sum_{t=1}^{T} \log p_{\text{CE}}(y_t^* \mid y_{\lt t}, x)$$$$\text{SB} = \left(\prod_{n=1}^{4} P_n\right)^{1/4}, \quad P_n = \frac{\sum_{t=1}^{T}\sum_{c \in \text{ref}_n} p_{\text{SB}}(\vec{c} \mid t, x)}{T - n + 1}$$这里 $p_{\text{CE}}$ 是 CE 头产生的概率分布,$p_{\text{SB}}$ 是 SB 头产生的概率分布,$\text{ref}_n$ 是参考译文中长度为 $n$ 的 n-gram 集合。
受限 softmax
全表 softmax 在 $V$=56,652 上计算分母,每个 token 的平均概率 $\approx 1/V \approx 1.8\times10^{-5}$,梯度被均匀稀释。语言系统碰撞常数 $K_{\text{lang}} \approx 0.003$ 指出有效碰撞空间仅有 $k = K_{\text{lang}} \cdot V \approx 170$ 个词。
受限 softmax 只在 top-$k$ + 参考词 ∪ 上归一化:
$$p_{\text{SB}}(v \mid t, x) = \frac{\exp(z_{t,v}) \cdot \mathbf{1}(v \in \mathbb{K})}{\sum_{v' \in \mathbb{K}} \exp(z_{t,v'})}$$其中 $\mathbb{K} = \text{topk}(z_t, k) \cup \text{ref}$ 为碰撞桶集合。
梯度分析
对 SB 头输出权重 $W_{\text{SB}}$ 的梯度:
$$\frac{\partial \mathcal{L}}{\partial W_{\text{SB}}} = \mathcal{L}_{\text{CE}} \cdot (-\alpha) \cdot \frac{\partial \text{SB}}{\partial W_{\text{SB}}}$$其中 $\partial \text{SB} / \partial W_{\text{SB}}$ 通过受限 softmax 反传。由于分母 $|\mathbb{K}| \approx 190$(vs 全表 56,652),梯度量级放大约 300 倍,从噪声水平($\sim 10^{-5}$)提升到与 CE 可比($\sim 10^{-2}$)。
对共享 LSTM 参数 $\theta$ 的梯度:
$$\frac{\partial \mathcal{L}}{\partial \theta} = \underbrace{\vphantom{\frac{\partial}{\partial}}\big(1 + \alpha(1-\text{SB})\big) \frac{\partial \mathcal{L}_{\text{CE}}}{\partial \theta}}_{\text{CE 主导,因子 1.0--1.5}} + \underbrace{\vphantom{\frac{\partial}{\partial}}\mathcal{L}_{\text{CE}}(-\alpha) \frac{\partial \text{SB}}{\partial \theta}}_{\text{SB 辅助信号}}$$早期 $\text{SB} \approx 0$ 时 SB 贡献项 $\propto \mathcal{L}_{\text{CE}} \approx 11$(放大),后期 $\text{SB} \to 0.35$ 时 $\partial \text{SB}/\partial \theta \to 0$(梯度衰减)。α 从 0.5 提到 0.8 有效补偿了衰减,维持 $\nabla_{\text{SB}} \neq 0$ 到训练晚期。
┌─ out_ce (Linear) ── L_CE ──┐
LSTM ─ hidden_seq ─┤ ├─ L = L_CE × (1 + α × (1−SB))
└─ out_sb (Linear) ── SB ──┘
两个独立的 out 层共享同一个 LSTM。CE 头负责精确 token 学习,SB 头通过碰撞空间内的受限 softmax 提供 n-gram 覆盖度信号。
A8–A12 K_lang 扫描结果
4 epoch, H=256, E=256, seed=42:
| 实验 | k | BLEU ep0 | ep1 | ep2 | ep3 | 峰值 | vs CE |
|---|---|---|---|---|---|---|---|
| A8 CE-only | — | 2.80 | 3.02 | 3.27 | 3.45 ↗ | 3.45 | baseline |
| A9 DH | 50 | 3.27 | 3.35 | 2.75 | 2.87 | 3.35 | −0.10 |
| A10 DH | 170 | 3.18 | 3.31 | 3.63 | 3.43 | 3.63 | +0.18 |
| A11 DH | 500 | 2.93 | 2.84 | 3.09 | 2.92 | 3.09 | −0.36 |
| A12 DH | 56652 | 3.03 | 3.35 | 3.24 | 3.21 | 3.35 | −0.10 |
k 值画出倒 U 曲线
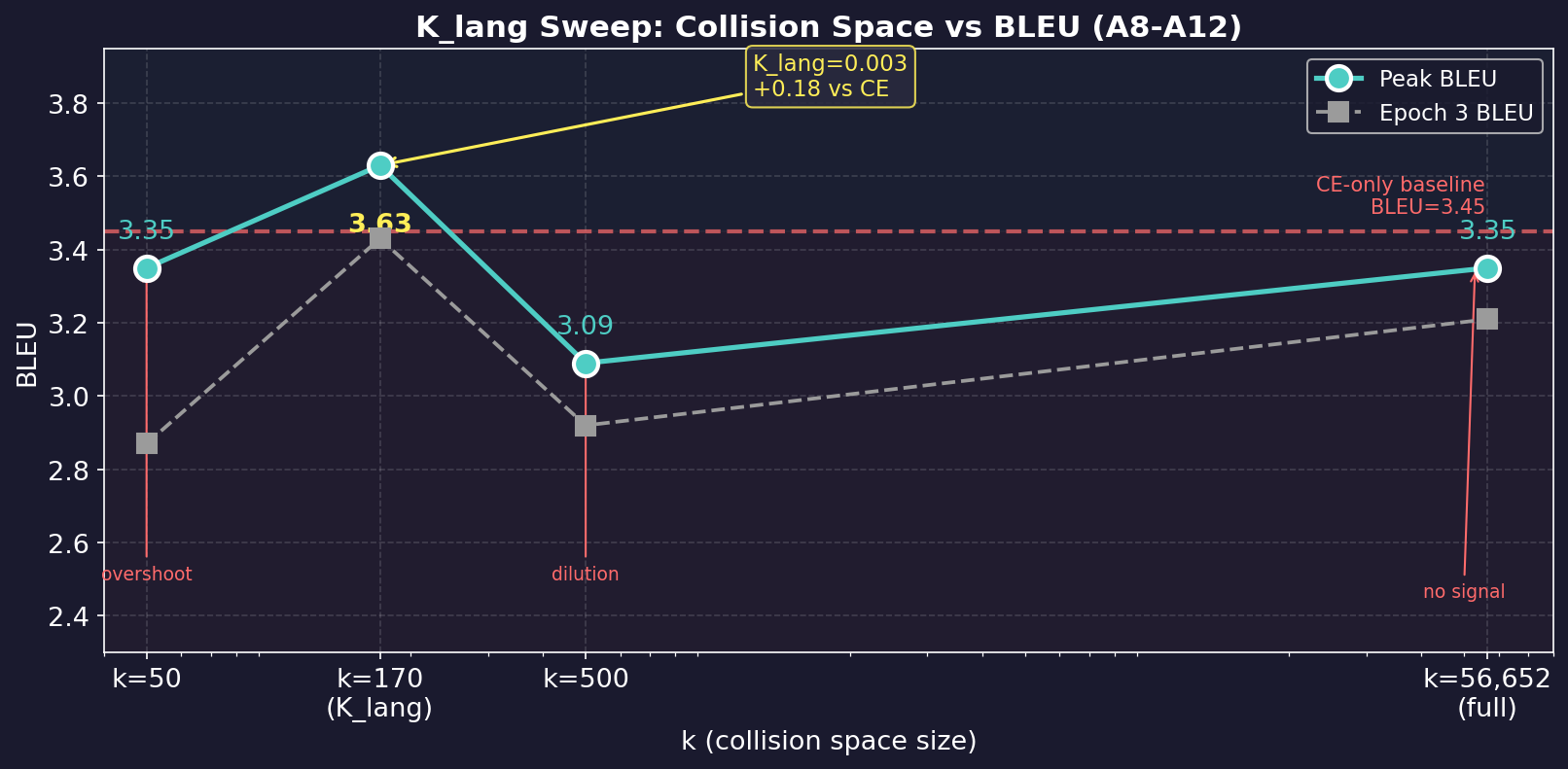
梯度放大 333 倍生效了——但只在合适的桶数上。桶太少(50),梯度太猛导致超调;桶太多(>500),稀释回噪声。
核心对比:A10 vs A12
同样的双头结构,同样的 CE×SB 乘法损失,唯一变量是 softmax 分母——170 vs 56652。
- A12(全表):SB_head 的
∇out_sb始终在 0.01-0.04 量级,而∇out_ce在 0.24-0.29——信号完全被 CE 淹没 - A10(170):早期
∇sb=0.10vs∇ce=0.71(7×),SB 头真正参与了学习
SoftBLEU 在 Attention 上首次显著超越 CE 基线。K_lang 碰撞理论验证成立。
A13–A15:梯度衰减修复
A10 的 SB 头梯度在 ep3 衰减到 ∇sb=0.00。测试两种修复方向——换函数形式 vs 加大 α:
| 实验 | 配置 | BLEU ep0 | ep1 | ep2 | ep3 | ep4 | 峰值 |
|---|---|---|---|---|---|---|---|
| A10 | linear α=0.5 | 3.18 | 3.31 | 3.63 | 3.43 | — | 3.63 |
| A13 | sqrt β=0.5 α=0.5 | 2.99 | 3.17 | 3.24 | 3.07 | 2.89 | 3.24 |
| A14 | sqrt β=0.3 α=0.3 | 2.55 | 3.07 | 3.24 | 3.20 | 2.94 | 3.24 |
| A15 | linear α=0.8 | 3.28 | 3.47 | 3.74 | 3.77 | 3.68 | 3.77 |
结论:换函数形式(sqrt)反降——梯度因子太小(β=0.5 时仅 0.5-0.63×线性)。直接加大 α 从 0.5 到 0.8,SB 头梯度晚期 ∇sb=0.02-0.11 未衰减到零,BLEU 从 3.63 飙到 3.77(+9.3% vs CE-only)。
当前最优:A15:k=170 (K_lang), multiply_linear, α=0.8, BLEU=3.77。
未解问题
- 峰后衰退——即使 α=0.8,BLEU 仍从 ep3=3.77 滑到 ep4=3.68。可能需 α 渐进升温(
--sb-alpha-step) - 真实 n-gram——当前 2/3/4-gram 仍是几何衰减占位,只有 1-gram 是 scatter_add
相关文献:可微 BLEU 的学术谱系
可微 BLEU 有两条路——RL 采样估计和直接可微替代。我们的 K_lang restricted softmax 属于后者,但与已有工作在关键细节上不同。
核心对比
| 方法 | 作者/发表 | 可微方式 | softmax 分母 | 架构 | 场景 |
|---|---|---|---|---|---|
| Ours (K_lang) | — | 1-gram soft 匹配, 限制梯度到碰撞桶 | 170 (topk+ref) | 双头 CE×SB | 自回归 Attention |
| BoN Difference | Shao et al. AAAI 2020 | Bag-of-Ngrams 直接最小化 | 全表 56K | 单头混合 | 非自回归 NAT |
| Probabilistic N-gram Matching | Shao et al. EMNLP 2018 | 概率 n-gram 匹配可微目标 | 全表 | 单头 | 自回归 NMT |
| Seq-Training for NAT | Shao et al. CL 2021 | BoN + REINFORCE 混合 | 全表 | 单头 | NAT |
| MRT | Shen et al. ACL 2016 | 采样 BLEU 期望梯度 (REINFORCE) | — | 单头 CE | 自回归 NMT |
详细分析
BoN Difference (arXiv:1911.09320):将 Bag-of-Ngrams (BoN) 差异直接作为可微 loss,在 NAT 上 +5 BLEU。与我们的 1-gram soft 匹配核心思想一致,但他们在全 vocabulary 上做 softmax——NAT 的基线 BLEU 只有 10-15,梯度稀释问题不如我们的 3.x BLEU 底线明显。无人提出限制 softmax 分母到碰撞空间。
Probabilistic N-gram Matching (arXiv:1809.03132):EMNLP 2018,用概率 n-gram 匹配计算训练时未来词的匹配度,同时做 greedy search 缓解 exposure bias。+1.5 BLEU。我们的 SoftBLEU 可以视为其简化版(省去搜索,保留概率匹配)——但他们也没限制分母。
MRT (arXiv:1606.02006):ACL 2016,采样 k 个翻译候选,用 BLEU 加权梯度。n-gram 上的 BLEU 精确但梯度方差高。我们的方案恰好相反——梯度确定性低方差(soft 匹配),但丢失 n-gram 结构。
K_lang Restricted Softmax 的新颖性
三条分叉点:
-
碰撞空间限制:BoN 和 N-gram Matching 都假设 softmax 在整个 vocabulary 上是有效的——这在 BLEU 15+ 的系统上成立(概率峰值集中)。但在 BLEU 3.x 的小模型上,softmax 概率被 56K 分母均摊到噪声水平。K_lang 理论指出有效碰撞桶只有 170 个,把分母从 56652 砍到 170——这在前人工作中未见。
-
双头独立梯度:前人用单头(同一个 out layer 接收 CE+BLEU 混合梯度),导致 CE 的强梯度压制 BLEU 的弱梯度。我们的双头架构(
out_ce和out_sb两个独立的 Linear 层共享 LSTM)让两个信号在 LSTM 层面乘法叠加,不在 out 层打架。 -
乘法损失
CE × f(1−SB):CE+SB 的加法混合假设两个信号独立,乘法假设条件依赖——这与 n-gram 的马尔可夫链统计性质一致。但形式f(x) = 1 + 0.5x在 SB→0.35 时退化,需要更激进的函数形式(指数等)。
K_lang 框架的最终形态:四层 hash,桶数与深度互补
Phase 2 到 Phase 6 跨越了 Attention → Transformer 的架构鸿沟,但 K_lang 碰撞理论跨架构成立:
四层 hash 压缩表
| 层 | 操作 | 词级 (56K) | BPE (8K) | 碰撞桶数变化 |
|---|---|---|---|---|
| 1. Embedding | token → R^d | 56,652 | 8,000 | 7× 压缩 |
| 2. Hidden (LSTM/Attention) | R^d → R^h | 256/512 | 256/512 | 参数量决定 |
| 3. Decoder/Output | R^h → R^V | 56,652 | 8,000 | 7× 压缩 |
| 4. Vocab 碰撞 | softmax(z) |
` | V | =56K → K_lang× |
BPE 以 7× 因子压缩了第 1、3、4 层的桶数。
桶越少,深度要求越高
Phase 6 实验结果直接验证了这一点:
$$\text{d256/3L (11.6M) → 10.66 BLEU}$$$$\text{d256/6L (17.2M) → 11.70 BLEU}$$
$$\text{d512/6L (56.4M) → 8.18 BLEU (过拟合)}$$
BPE 把 vocab 从 56K 压到 8K——第 4 层的碰撞桶从 170 缩到 24。在 24 个桶里区分 token,每个桶承担 7× 更多的语义负载。浅模型(3L)的 hidden 层没有足够深度把这些语义分离开。深模型(6L)每层递进一步,在 hidden 维度里重建了被压缩的分辨率。
这就是 hash 碰撞框架的完整闭环:
$$K_{\text{lang}} \approx 0.003$$$$N_{\text{collision}} = K_{\text{lang}} \times |V|$$
$$N_{\text{word-level}} = 170, \quad N_{\text{BPE}} = 24$$
170→24 的桶压缩需要 3L→6L 的深度补偿。深度不是越大越好——d512/6L 的 56M 参数在 160K 句 IWSLT14 上过拟合,反向证明桶的容量有一个上限:桶再多,没有足够数据灌满就成了空洞。
推论:对于给定的训练数据量,存在最优桶数 × 最优深度的乘积——这解释了 B3 (d256/6L, 17.2M, 24 桶) 为什么是最优甜点。
May the Code be with us.
License: GPLv3
本文《SameTime》系列采用 GNU 通用公共许可证第三版 (GNU General Public License v3.0) 协议进行开源发布与分发。允许任何形式的复制、修改和分发,但必须继承相同的开源协议,承认在算力宇宙中所有的迭代与变异。