递归砍半做回归
两种学一条线的思路
给定数据点,学一条最优穿过它们的线。有两种完全不同的办法。
方法 A:拧线(梯度下降)
从一根随机线开始,每个数据点像一个磁铁——线离它远了就被拉过来,离近了被弹开。反复拧,拧到再拧也改善不了为止。
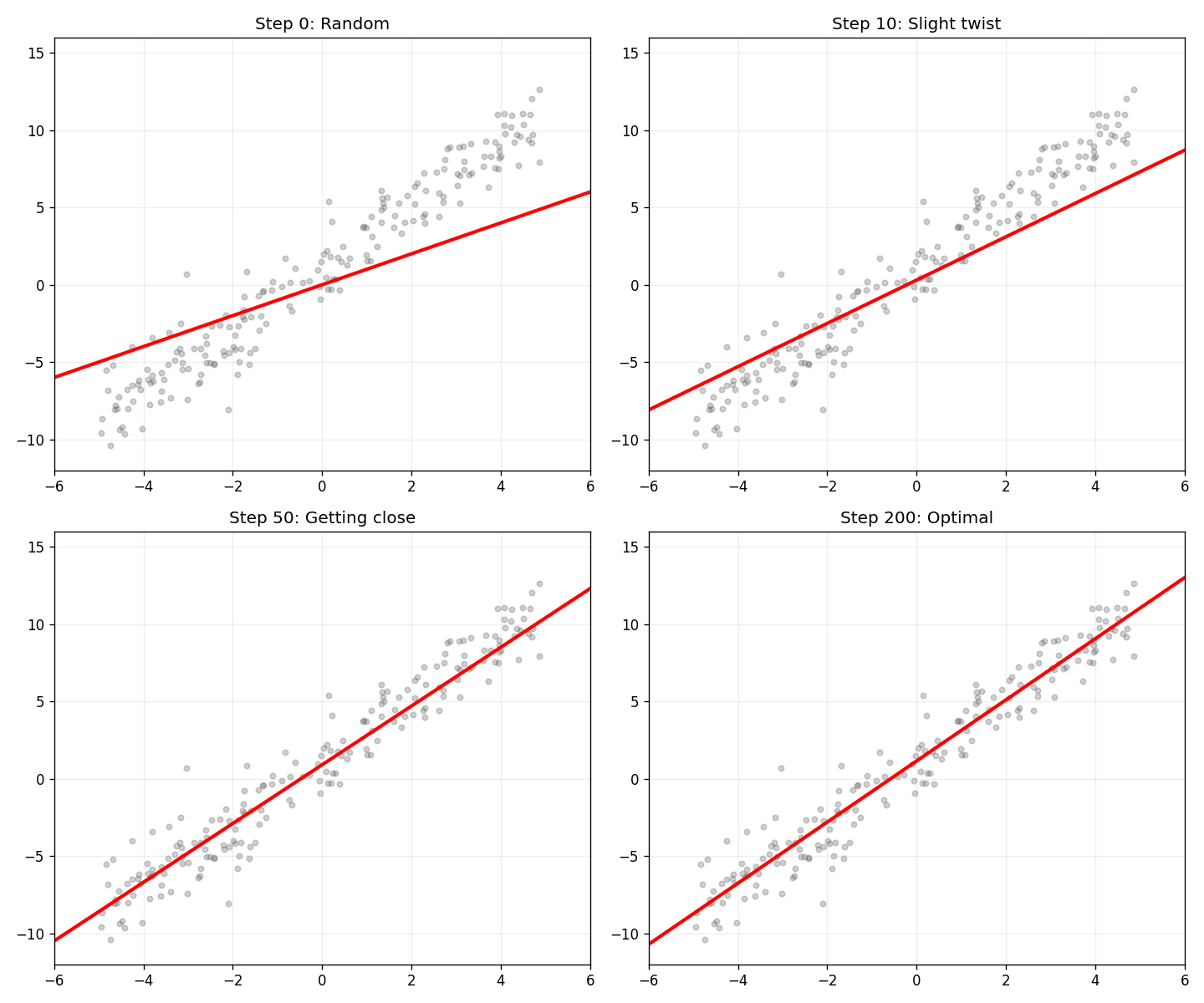
4 步——从随机到最优。2 个参数 (w, b),通过 1000 个点的「引力」逐次变形。
方法 B:砍空间(递归排除)
不拧线。把 x 轴砍成两半→四半→八半→……每片叶子只存一个值(这区域内 y 的平均)。砍到够细,这些平线就会逼近最优线。
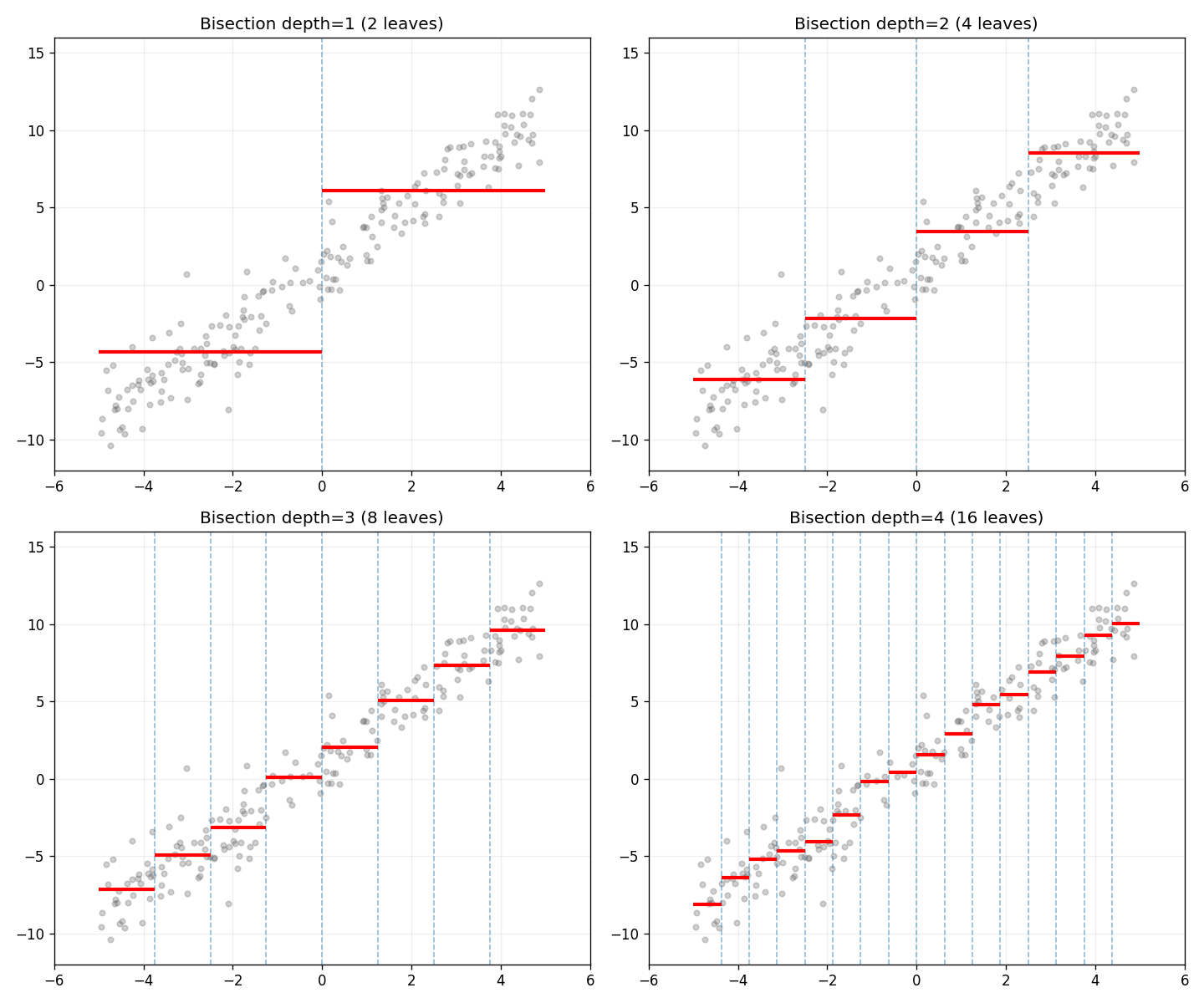
depth=1: 2 段平线,MSE=10.07。depth=4: 16 段平线,MSE=2.32——追平梯度下降了。
两种思路,同一个实验
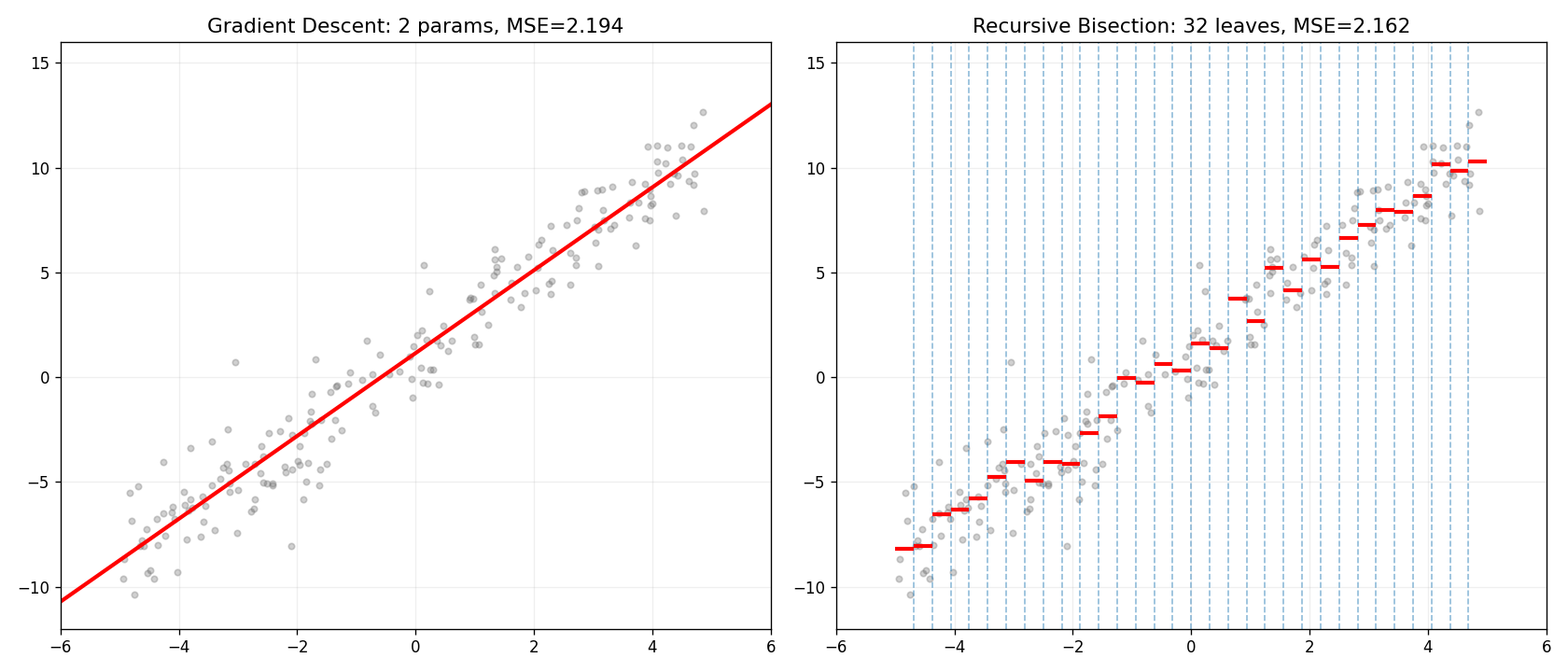
左边 (拧线): 2 个参数 (w, b),MSE=2.194
右边 (砍半 depth=5): 32 片叶子,MSE=2.162
不需要梯度、不需要求导、不需要反向传播——只靠空间二分排除,就能追平连续优化。
参数更多(32vs2),但每个参数的计算成本为零(只是区域均值)。不需要学习率、不需要 epoch 调优。
为什么这跟 SPR 有关
Transformer 的输出层是:hidden(256 维) → 矩阵乘(256×32000) → softmax → 选词。
这相当于「对 32000 个候选词每一个都问一遍:是不是你?」——就像你做线性回归时,对 x 轴上的每一个点都算一遍「线到这里的距离」。而砍半树的做法是「只问 15 次二分判定」,每次排除一半候选空间。
两者在数学上等价——都在逼近同一个最优解。但砍半不需要 O(V) 的矩阵乘法。
关键发现
| 拧线(梯度下降) | 砍空间(递归排除) | |
|---|---|---|
| 操作 | 拧一整条线 | 砍一个区域 |
| 参数 | 2 个 (w, b) | 16-32 片叶子 |
| 是否需要梯度 | ✅ 需要 | ❌ 不需要 |
| MSE depth=4 | 2.194 | 2.324 (追平) |
| MSE depth=5 | 2.194 | 2.162 (反超) |
一样的精度,完全不同的实现路径。 这就是 SPR 的理论起点:输出层可以是一棵递归判定的树,不需要稠密矩阵。
下一步
- 把树从一维 x 轴扩展到 256 维 hidden 空间
- 每个树的内部节点不砍 x 轴,而是砍 hidden 向量的一个方向
- 实现静态 SPR 输出层,与 T.STD.CE-033 基线对比
实验代码:holds/SameTime/experiments/tree_regression.py
May the Code be with us.
License: GPLv3