Transformer 从零到一
不是因为它更聪明——是因为它把整个句子当一张全连接图,一次算完。
1. RNN 为什么不行
RNN 的翻译流程:读第 1 个词 → 更新隐藏状态 → 读第 2 个词 → 更新隐藏状态 → … → 读最后一个词 → 开始解码。
"die katze schläft" → h1 → h2 → h3 → 解码 "the cat sleeps"
这里有一个根本问题:50 个词共用一条链。第 50 个词的梯度要穿过 49 层才能传到第 1 个词。LSTM 用三个门(遗忘门、输入门、输出门)延缓了梯度消失,但治标不治本。
用 Phase 1 LSTM 跑 IWSLT14 翻译,最佳 BLEU 只有 3.06。跑 5 个 epoch 就过拟合——梯度链太长,信息衰减太快,模型记不住长程依赖。
Transformer 的方案是:不串行了。整个句子一次性扔进去,让每个词同时关联所有其他词。
但这个方案不免费——代价是两方面的膨胀:
1. Hidden 膨胀。 LSTM 的 encoder 输出是 (num_layers, B, hidden_size),比如 2 层 256 维 = (2, B, 256),只存最终状态 512 个浮点数。Transformer 的 encoder 输出是 (B, S, d_model) ——每个位置都保留了完整的 d_model 维向量。句长 S=128、d_model=512 时,encoder 输出是 65536 个浮点数,是 LSTM hidden 的 128 倍。
2. 空间复杂度 O(n²)。 Self-Attention 计算所有词对之间的分数,Attention 矩阵是 (B, heads, S, S)。S=128 时是 128² = 16384 个元素/头,S=512 时是 262144。相比之下 LSTM 的复杂度是 O(n)——每步只看当前输入和 hidden state。这就是为什么长序列(长文本、高像素图像)上原生 Attention 会撞显存墙。
代价之三是:需要位置编码。Attention 本身不认识顺序——而 RNN 天然有位置信息,因为词是一个一个按顺序灌进去的,位置即处理顺序,不需要额外标记。Transformer 一次性吞入整句,词的先后关系全部丢失,必须显式注入 sin/cos 位置信号补回来。常被误称为"时序信息",其实不是时序——是位置信息,跟时间无关,跟排在哪儿有关。
那代价花得值吗? 一个直接的反问:把 LSTM 的 hidden_size 膨胀到和 Transformer 同等参数量,能追上来吗?事实证明不能。LSTM BiLSTM + Attention 在 IWSLT14 上的上限是 BLEU 3.77,而同等参数量的 Transformer 是 11.49。
差距不是参数量——是信息流动方式。
改变这个架构,改变的是矩阵本身的形状。 LSTM 的梯度沿时间步串行累积——error signal 穿过 n 层 cell state 逐层回传,路径长度 O(n)。Transformer 的梯度通过 Attention 权重矩阵直连——第 i 个位置到第 j 个位置的梯度走一次 matmul 的链式法则就到,路径长度 O(1)。前者是串联电路,后者是全连接总线的平行电路。
这是一个数据结构层面的观察。 O(n) 和 O(1) 不是运算步数的差异——是矩阵的拓扑结构从链变成了图。RNN 的隐藏状态链是一个一维序列,梯度沿这条线逐站传递。Attention 的权重矩阵是一个二维邻接矩阵,任意两点直连,梯度在各位置间均匀分布。形状的改变先于算法的改变。 后面拆解的 Self-Attention、Multi-Head、LayerNorm,都是在"全连接邻接矩阵"这个数据结构上展开的具体计算规则。
| LSTM (即使扩大) | Transformer | |
|---|---|---|
| 信息瓶颈 | 单管滴管:整句逐个吸入 (num_layers, B, hidden_size) 一个定长向量,解码器只能从这根管里拆 |
(B, S, d_model) 按位置展开,解码器直接查源句任意位置 |
| 梯度路径 | O(n):第 50 个词的梯度穿 49 层 RNN step 才到第 1 个词 | O(1):任意两个位置通过 Attention 权重直连 |
| 并行性 | 串行:必须等上一步算完,GPU 大量空闲 | 全并行:所有位置一次 matmul 算完 |
LSTM 的 hidden state 本质是一个单管滴管——不管管子多粗(hidden_size=512、1024、2048),一次只能吸一个孔,50 个词的语义必须逐个挤过去。Transformer 是多通道移液器——多个吸头对准矩阵的一整行,一次操作同时处理所有位置。这才是根本差别。
RNN 不是废了。它在这里只是碰巧被拿来解决 NLP——NLP 需要全距离依赖,RNN 的链式拓扑先天吃亏。但在流式信号处理、实时控制、低延迟嵌入式推理里,时序本身就是信息,串行不是缺陷是特性,RNN 依然是英雄之刃。
怎么做到的?答案就是 Self-Attention。
2. Self-Attention —— Q、K、V
Self-Attention 的直觉:我是一个词,我拿三个问题去问整句话里的每个词。
| 组件 | 含义 | 直觉 |
|---|---|---|
| Q (Query) | “我想找什么?” | 当前词的搜索意图 |
| K (Key) | “我有什么?” | 每个词的标签/索引 |
| V (Value) | “我值多少?” | 每个词的实际语义内容 |
Q、K、V 都来自同一个输入序列,不是来自词表。 输入张量
(B, T, d_model)分别过三个不同的线性投影W_q、W_k、W_v(都是nn.Linear(d_model, d_model)),得到三个形状完全相同的张量。词表只在两处出现——入口的 Embedding(token → d_model,本质是一键查表)和出口的 Linear(d_model → vocab_size logits)。中间的 Q、K、V 全程在 d_model 空间运算,跟词表大小无关。
这些 W 参数本质是寄存器。 不管是 RNN 的
W_hh(h_{t-1}→h_t 的时间连接),还是 Transformer 的W_q/W_k/W_v(位置 i→位置 j 的图连接),里面存的都是一个一个的标量参数——梯度反向传播时,值就积累在这些寄存器里。RNN 积的是串行时间量,Transformer 积的是全连接边权重。拓扑不同,寄存的逻辑相同。这些寄存器之所以排列成矩阵,是为了适应物理世界的算力架构。 GPU 的并行单元按矩阵瓦片调度——寄存器排成矩阵,才能被一次
matmul调起所有通道。不是"矩阵天然适合存参数",是"参数必须排成矩阵才能用硬件"。
流程:
1. 每个词过一个线性层 → 得到自己的 Q, K, V
2. Q 和所有 K 做点积 → 得到 "当前词和每个词的匹配分数"
3. 除以 √d_k → 缩放防梯度饱和(点积方差随维度增长)
4. softmax → 归一化成分数权重
5. 权重 × V → 加权求和 → 当前词的上下文表示
公式:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$为什么除以 √d_k? 假设 Q 和 K 的每个元素独立同分布,均值为 0,方差为 1。点积 q·k 的方差是 d_k。d_k 大了之后,点积值可能很大,会让 softmax 落入梯度平坦区(极低或极高的 softmax 值梯度接近 0)。除以 √d_k 把方差压回 1,保持 softmax 在"敏感区"。
代码对照——model.py:59:
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
2.1 Mask —— 边界与未来
让模型知道"哪句话在哪结束、哪个词不能偷看"。Encoder 屏蔽 padding,Decoder 用下三角屏蔽未来词。
# Encoder mask (model.py:115): padding 位置不能参与
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # (B, 1, 1, S)
# Decoder mask (model.py:167): 未来词不能偷看
tgt_mask = torch.tril(torch.ones(1, 1, T, T, device=tgt.device))
# 比如 T=4:
# [[1, 0, 0, 0],
# [1, 1, 0, 0],
# [1, 1, 1, 0],
# [1, 1, 1, 1]]
3. Multi-Head —— 8 个专家各自打分
一个 Attention Head 只从一种角度衡量"相似度"。Multi-Head 让 8 个头各自在低维子空间(d_k = d_model / 8)独立计算 Attention,然后拼接起来。
d_model = 512, num_heads = 8 → d_k = 64
不是 "把 512 维劈成 8 段" ——
而是 "每个头都有权看全部 512 维,但只输出 64 维"
代码——model.py:46-65:
# 四个线性投影
self.W_q = nn.Linear(d_model, d_model) # 512 → 512(拆分到 8 头 × 64)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model) # 拼接后投影回 512
def forward(self, query, key, value, mask=None):
B = query.size(0)
Q = self.W_q(query).view(B, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(key).view(B, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(value).view(B, -1, self.num_heads, self.d_k).transpose(1, 2)
# → (B, num_heads, T, d_k)
scores = Q @ K.transpose(-2, -1) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
attn = F.softmax(scores, dim=-1)
# → (B, num_heads, T, d_k)
out = attn @ V
out = out.transpose(1, 2).contiguous().view(B, -1, d_model)
# → (B, T, d_model)
return self.W_o(out)
关键 view 和 transpose:
W_q 后: (B, T, 512)
view(B, T, 8, 64) → (B, T, 8, 64)
transpose(1, 2) → (B, 8, T, 64) # 把 "头数" 当作 batch 维并行算
view不分配新内存,不拷贝,不初始化。 它只是在 W_q 刚算出来的 512 个浮点数上换一个形状标签——把同一块内存重新标记为 8 组 × 64。view前是 W_q 的有效计算结果,view后读到的就是那些值,不存在未初始化的随机残值。512 = 8 × 64,严丝合缝,无残留。
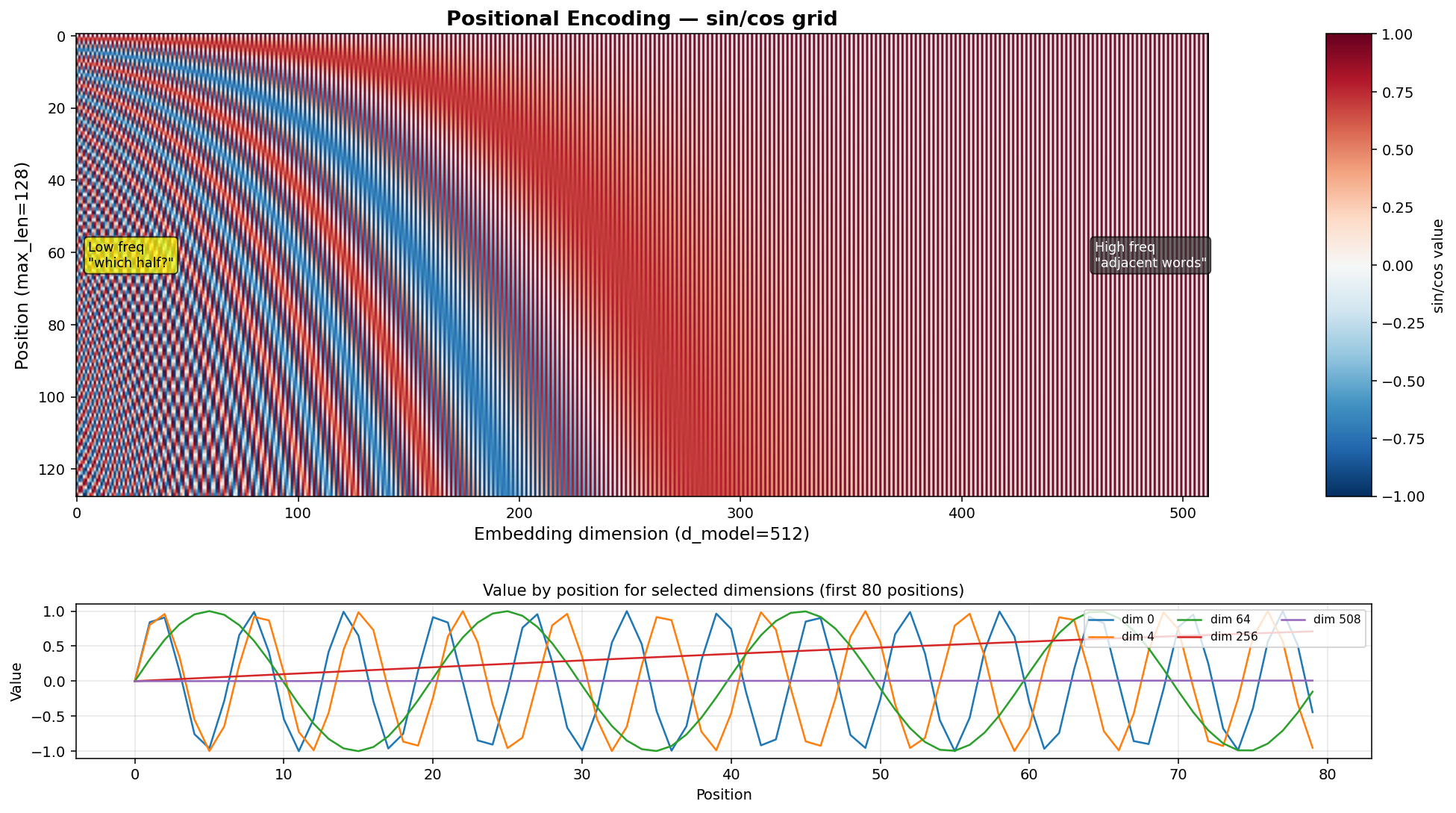
4. Positional Encoding —— 位置从哪来
Self-Attention 不分词序:“A 打了 B” 和 “B 打了 A” 在纯 Attention 里等价。需要注入位置信息。
Transformer 选 sin/cos 函数,每个维度用不同频率:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
维度 0-1:频率最低(接近 DC)—— 编码"这句话有多长"
维度 510-511:频率最高 —— 编码"相邻词的关系"
可视化——左边是 128 个位置 × 512 维的 sin/cos 栅格,右边是几条维度线随位置的变化:
代码——model.py:22-30:
pe = torch.zeros(1, max_len, d_model)
pos = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[0, :, 0::2] = torch.sin(pos * div)
pe[0, :, 1::2] = torch.cos(pos * div)
self.register_buffer("pe", pe) # 不是可训练参数!持久化但不求梯度
为什么选 sin/cos?因为 sin(a+b) 可以用 sin(a) 和 cos(b) 线性组合表示——这让"相对位置"可以被 Attention 学习到,而不只是"绝对位置"。
5. FFN + Residual + LayerNorm
每个 Attention 层后面跟一个 Position-wise Feed-Forward Network:对每个位置独立做相同的两层 MLP。
FFN(x) = ReLU(xW1 + b1)W2 + b2
512→2048 2048→512
代码——model.py:72-80:
class FFN(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
self.fc1 = nn.Linear(d_model, d_ff) # 升维
self.fc2 = nn.Linear(d_ff, d_model) # 降回来
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.fc2(self.dropout(F.relu(self.fc1(x))))
Residual Connection 是 Transformer 能堆到 100 层的核心原因:
x = x + Sublayer(x)
梯度可以通过残差路径 x 直达浅层,不用穿过 Sublayer 的矩阵乘法——这就是"高速公路"。
LayerNorm 归一化每条样本的特征维度(d_model),消除层间的数值漂移:
$$\text{LayerNorm}(x) = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta$$本代码用 Pre-LN(现代惯例)——Norm 在前,Sublayer 在后:
原始论文 Vaswani 2017 (Post-LN):
x = LayerNorm(x + Sublayer(x))
现代实现 (Pre-LN, 更稳定):
x = x + Sublayer(LayerNorm(x))
区别:Post-LN 的残差梯度必须先穿过 LayerNorm 的归一化再流入浅层——随着层数变深,归一化累积把梯度压得太小,导致深层几乎不更新。Pre-LN 让梯度直接走残差路径,不经过 Norm——这就是为什么 Pre-LN 能训 100 层而 Post-LN 不行。
对应代码——model.py:97-99:
# Pre-LN: norm 在里面,残差在外面
x = x + self.dropout1(self.self_attn(self.norm1(x), self.norm1(x), self.norm1(x), mask))
x = x + self.dropout2(self.ffn(self.norm2(x)))
上面把零件拆开讲完了——下面拼起来,看一整句数据怎么穿过 Encoder 和 Decoder。
6. Encoder-Decoder 全流程
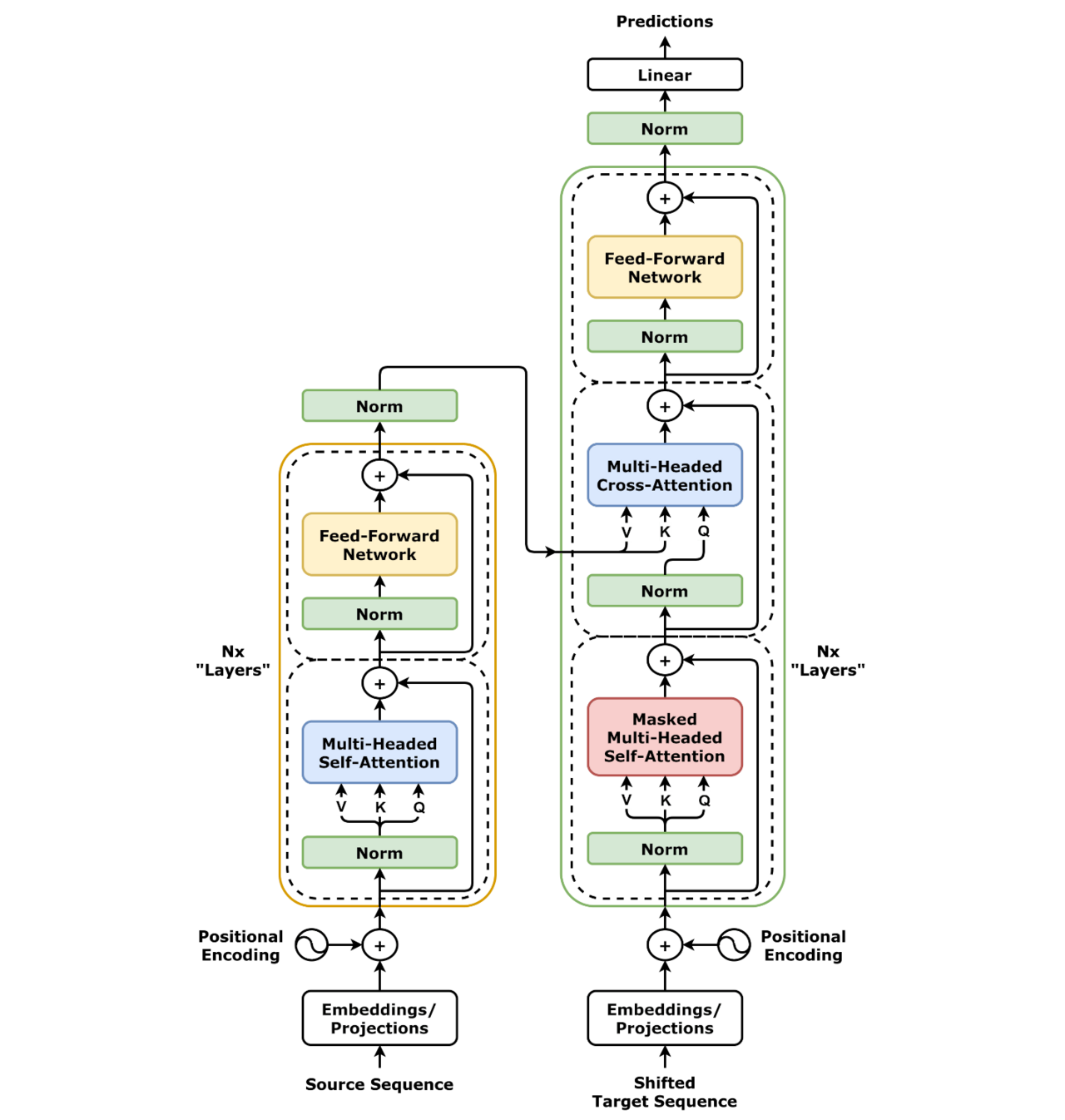 来源:Wikipedia / “Attention Is All You Need” (Vaswani et al., 2017)
来源:Wikipedia / “Attention Is All You Need” (Vaswani et al., 2017)
数据流逐阶段拆解:
┌─ Encoder ─┐ ┌─ Decoder ──────────┐
src: "die katze" Embed+PosEn Embed+PosEn tgt: "<sos> the cat"
│ │ │ │
▼ ▼ ▼ ▼
[1, 4] [1, 4, 512] [1, 5, 512] [1, 5]
│ │
▼ ▼
N×EncoderLayer N×DecoderLayer
┌ Self-Attn ─┐ ┌ Masked Self-Attn ─┐
│ + FFN │ │ Cross-Attn │ ← Q 来自 decoder
│ + FFN │ │ + FFN │ ← K/V 来自 encoder
└────────────┘ └───────────────────┘
│ │
▼ ▼
Final LayerNorm Final LayerNorm
│ │
│ ▼
src_mask──────────┼─→ cross_attn ──→ Linear(d_model → vocab)
│ │
▼
[1, 5, 32000] ← logits
每一层的 tensor 形状变化(d_model=512, vocab=32000, 例句 src=4 token, tgt=5 token):
| 步骤 | 形状 | 说明 |
|---|---|---|
| Embedding(src) | (B, 4, 512) | token → 512 维向量 |
| ×√512 + PositionalEncoding | (B, 4, 512) | 加位置信息 |
| EncoderLayer × N | (B, 4, 512) | N 层 Self-Attn + FFN |
| Final LayerNorm | (B, 4, 512) | 归一化 |
| — 交棒 — | ||
| Embedding(tgt) | (B, 5, 512) | 目标端也 embed |
| ×√512 + PositionalEncoding | (B, 5, 512) | |
| DecoderLayer × N | (B, 5, 512) | Self-Attn(masked) + Cross-Attn + FFN |
| Final LayerNorm | (B, 5, 512) | |
| Linear(512 → 32000) | (B, 5, 32000) | 投影到词表 |
关键洞察:feature 维度全程不变。 从 Embedding 到 Final LayerNorm,每一层的输出都是
(B, T, d_model)。没有"先压缩到 hidden state 再解开"的过程——这就是 Transformer 和 LSTM 最本质的架构差异。
对比 LSTM(Phase 1/2 的 Encoder-Decoder):
LSTM Transformer
──── ───────────
Encoder: src → [LSTM × N] → hidden src → [Self-Attn × N] → enc_out
(B,4,256) → (2, B, 256) (B,4,512) → (B,4,512) ← 保持!
Decoder: hidden → [LSTM × N] → logits tgt → [Self/Cross-Attn × N] → logits
(2, B, 256) → (B, 5, 32000) (B,5,512) → (B,5,512) → (B,5,32000)
LSTM 的 hidden 是 (num_layers, B, hidden_size) ——一个固定大小的向量。50 个词的语义被压缩到 256 个浮点数里,解码器必须从这个压缩包里逐字拆出译文。
Transformer 的 enc_out 是 (B, S, d_model) ——按位置展开的矩阵。解码器的 Cross-Attention 可以直接盯着源句子的每个位置查,不用从压缩包里猜。
这就是"关联"比"压缩"更有效的根本原因。
代码对照——model.py:189-191,整个流程被压缩成三行:
class Transformer(nn.Module):
def forward(self, src, tgt, src_len):
enc_out, src_mask = self.encoder(src, src_len)
return self.decoder(tgt, enc_out, src_mask)
Cross-Attention 的关键(model.py:143-144)——Q 来自 decoder,K/V 来自 encoder:
# decoder 的 cross-attention:
x = x + self.dropout2(self.cross_attn(
self.norm2(x), # ← Q: decoder 的当前状态("我想翻译出什么")
enc_out, # ← K: encoder 的输出("源句子里有什么")
enc_out, # ← V: encoder 的输出("源句子的语义")
src_mask # ← 屏蔽源句子的 padding
))
以上是推理时的数据流——下面看训练时怎么让模型"学会"翻译。
7. 训练三件套
Teacher Forcing:训练时不喂自己的预测结果,而是喂正确答案的上一步。解码 "<sos> the cat" 时,第一步输入 <sos> 应该输出 the,第二步输入 the 应该输出 cat——但用的是真实的目标序列,不是模型自己生成的。
代码——train_wmt14.py:182:
logits = model(src, tgt[:, :-1], src_len)
# tgt[:, :-1] = "<sos> the cat" → 期望输出 = "the cat </s>"
# tgt[:, 1:] = "the cat </s>" → 损失计算目标
Label Smoothing:不要让模型对正确答案有 100% 的确信。把正确答案的概率从 1.0 降为 0.9,其他词瓜分 0.1。这防止模型过度自信,提升泛化。
criterion = torch.nn.CrossEntropyLoss(ignore_index=0, label_smoothing=0.1)
Warmup Scheduler:刚开始训练时学习率从 0 线性增长到目标值,然后衰减。前几步太大 → 梯度爆炸;太小 → 收敛慢。Warmup 给出了一个"缓慢启动"的安全缓冲区。
lr = d_model^(-0.5) * min(step_num^(-0.5), step_num * warmup^(-1.5))
8. 代码全图:model.py 逐块标注
前面分模块讲完——这里是压缩版速查,按执行流排列,每个模块对应的行号和关键 tensor 流。不是替代前文,是让你回头找代码的时候一眼定位。
model.py 总览 (191 行)
═══════════════════════════════════════
[L16-35] PositionalEncoding
pe[pos, 2i] = sin(pos / 10000^(2i/d))
pe[pos, 2i+1] = cos(pos / 10000^(2i/d))
→ register_buffer, 不学
[L41-65] MultiHeadAttention
W_q, W_k, W_v, W_o: 四个独立的线性投影
view+transpose: (B, T, 512) → (B, 8, T, 64)
Q·K^T / √64 → softmax → ×V → concat → W_o
[L72-80] FFN
fc1: 512→2048 (ReLU) → dropout → fc2: 2048→512
每个位置独立,共享参数
[L87-100] EncoderLayer
norm1 → Self-Attention → +residual (dropout)
norm2 → FFN → +residual (dropout)
[L103-120] Encoder
Embedding → ×√d_model → +PositionalEncoding
→ EncoderLayer × N → Final LayerNorm
→ return (enc_out, src_mask)
[L127-147] DecoderLayer
norm1 → Masked Self-Attention → +residual
norm2 → Cross-Attention(Q=dec,KV=enc) → +residual
norm3 → FFN → +residual
[L150-176] Decoder
Embedding → ×√d_model → +PositionalEncoding
→ DecoderLayer × N → Final LayerNorm
→ Linear(512→32000) → logits
[L183-191] Transformer
enc_out, src_mask = encoder(src, src_len)
return decoder(tgt, enc_out, src_mask)
9. 从 NMT 到 GPT
Encoder-Decoder 架构适合机器翻译——有明确的"源"和"目标"。但 LLM(GPT 系列)只用 Decoder。
Encoder-Decoder(翻译):
src → [Encoder: 全连接 Attention] → enc_out
tgt → [Decoder: masked Self-Attn + Cross-Attn(enc)] → logits
Decoder-only(GPT):
input → [Decoder: masked Self-Attention] → logits
↑
causal mask 就是全部
(Cross-Attention 删了,因为没有 encoder)
只需要删掉 Cross-Attention,去掉 Encoder——Transformer 就退化成了 GPT。解码时逐 token 生成,每次用 causal mask 让当前位置后面的 token 不可见。
这就是 Transformer 的故事:从针对翻译的 Encoder-Decoder 设计,到成为所有 LLM 的通用骨架。不是因为"翻译"这个任务特殊——是因为 Self-Attention + Residual + LayerNorm 这三个东西的组合,恰好构成了一个能稳定堆叠到任意深度的通用序列处理器。
三句话带走:
- RNN 是单管滴管——梯度 O(n)、信息逐个挤过一根 hidden state 管;Transformer 是多通道移液器——O(1) 路径、全并行吸入一整行。
- 发动机是 Self-Attention(Q·K^T/√d × softmax × V),拼装上 Multi-Head、Pre-LN Residual、sin/cos Positional Encoding。
- Encoder-Decoder 是翻译特化版——删掉 Cross-Attn 和 Encoder 就是 GPT。
License: GPLv3 本文《Transformer 从零到一》系列采用 GNU 通用公共许可证第三版 (GNU General Public License v3.0) 协议进行开源发布与分发。允许任何形式的复制、修改和分发,但必须继承相同的开源协议,承认在算力宇宙中所有的迭代与变异。